By Gideon Kowadlo and David Rawlinson
Introduction
We’ve been building and testing AGI algorithms for the last few years. As the systems become more complex, we have found it ever more difficult to run meaningful experiments. To summarise, the main challenges are:- testing a version of the algorithm repeatedly and over some range of parameters or conditions,
- scaling it up so that it can run quickly,
- debugging: the complexity of the ‘brain’ makes visualising and interpreting its state almost as hard as the problem itself!
Whereas most AI testing frameworks are designed to facilitate a particular problem, we want to facilitate understanding of the algorithms used. Further, the algorithms will have complex internal state and be variably parameterised from small instances on trivial problems to large instances - comprising many computers - on complex problems. As such there will be a lot of emphasis on interfaces that allow the state of the algorithm to be explored.
These design goals mean that we need to look more at the enterprise and web-scale frameworks for distributed systems, than test harnesses for AIs. There's a huge variety of tools out there: Distributed filesystems, cloud resourcing (such as Elastic Compute), and cluster job management (e.g. many scientific packages available in Python). We'll design a framework with the capability to jump between platforms as available technologies evolve.
Developing distributed applications is significantly harder than single-process software. Synchronization and coordination is harder (c.f. Apache Zookeeper), and there's a lot of crud to get right before you can actually get to the interesting bits (i.e. the AGI). We're going to try to get the boring stuff done nicely, so that others can focus on the interesting bits!
Foundational Principles
- Agent/World conceptualisation
- For AGI, we have developed a system based around Experiments, with each Experiment having Agents situated in a World.
- Reproducible
- All data is persisted by default so that any experiment can be reproduced from any time step.
- Easy to run and use
- Minimal setup and dependencies.
- No knowledge of the implementation is required to implement a custom module (primarily the intelligent Agent or World in which it operates).
- Highly modular (Scalability)
- Different parts of the system can be customised, extended or overridden independently.
- Distributed architecture (Scalability)
- Modules can be run on physically separated machines, without any modification to the interactions between modules (i.e. the programmer’s perspective is not affected by scaling of the system to multiple computers).
- Easy to develop
- Code is open source.
- Code is well documented.
- All API’s well documented and using standard protocols (at the moment RESTful, in future could be websockets or other).
- Explorable / Visualisable
- High priority placed on debugging and understanding of data rather than simply efficiency and throughput. We don’t yet know what the algorithm should look like!
- All state is accessible, relations are can be explored.
- Execution is on demand (step-by-step) or automatic (until criteria, or batches of experiments completed).
- It must be easy for anyone to build a UI client that can explore the state of all parts of the system.
Conceptual Entities
We have defined a number of components that make up an experiment. We refer to these components as Entities, and give them a specific interface.
Each entity is a module. Use of particular entities is optional and extensible. A user will inherit the entities that they choose, and implement the desired functionality. Another modularisation occurs with the AGIEF Nodes. They communicate via interprocess conventions so that components can be split between multiple host computers.
Interprocess communication occurs via a central interface called the Coordinator, which is a single point of contact for all Entities and the shared system state. This also enables graphical user interfaces to be built to control and explore the system.
These concepts are expanded in the sections below.
Processing to update the state of Worlds and Agents will be compute-intensive. Many AI methods can easily be accelerated by parallel execution. Therefore, the system can be broken down into many computing nodes, each tasked with performing a specific computational function on some part of the shared system state. We hope to support massively parallel hardware such as GPUs in these compute nodes.
We will write the bulk of the framework and initial algorithm implementations in Java. Others can extend on this, or develop against the framework in other languages. We will also write a graphical user interface using web technologies that will allow easy management of the system.
Each layer is distinct, with strict separation. No layer has access to the layers above, which operate at a higher level of abstraction.
The Coordinator and Database are services. The Coordinator is shown at the centre, as described earlier (Architecture section), being the primary point of contact for Entities and potentially other clients such as a Graphical User Interface.
A similar perspective is shown in an expanded diagram below that illustrates the Database API module and the distributed implementation of the Coordinator in the Interprocess layer, enabling Entities to run on separate machines. This is just one possible configurations; there can be multiple slaves, each with multiple entities.
We looked at popular No-SQL web storage systems (basically key-value stores) which are very convenient and flexible due to the inherently dynamic, software-defined schemas and HTTP interfaces. However, we have a relatively static schema for our data, on which we will build utilities for managing experiments and visualising data. In addition, relational databases such as MySQL and PostgreSQL are beginning to offer HTTP interfaces as well. Whether we pick a NoSQL or Relational Database, we will require a HTTP interface.
A third perspective is the data model that represents the system in its entirety. This is the model implemented in the database.
The data model stores the entire system state, including hierarchy and relationship between entities, as well as the state of each entity. With a RESTful API exposing the database, we have a shared filesystem accessible as a service, essential for distributed operation and restoring the system at any point in time.
- World
- The simulated environment within which all the other simulated components exist.
- Agent
- The intelligent agent itself. It operates within a World, and interacts with that World and (optionally) other Agents via a set of Sensors and Actuators.
- Sensor
- A means by which the Agent senses the world. The output is a function of a subset of the World state. For example, a unidirectional light sensor may provide the perceived brightness at the location of the sensor.
- Actuator
- A means by which an Agent acts on the World. The output is a simulated physical action. For example, a motor rotating a wheel.
- Experiment
- The Experiment Entity is a container for a World, and a set of Agents (each of which have a set of Sensors and Actuators), and an Objective Function which determines the terminating condition of the experiment (which may be a time duration).
- Laboratory
- A collection of Experiments that form a suite to be analysed collectively. This may be a set of Experiments that have similar setups with minor parameter variations.
- ObjectiveFunction
- The objective function computes metrics about the World and/or Agents that are necessary to provide Supervised Learning or Reinforcement Learning signals. It might instead provide a multivariate Optimization function. The ObjectiveFunction is a useful encapsulation because it is often easy to separate objective measurements from the AI that is needed to achieve them.
Architecture
To enforce good design principles, the architecture is multi-layered and highly modular. Multiple layers (also known as multi-tier architecture) allows you to work with concepts that are at the appropriate level of abstraction, which simplifies development and use of the system.Each entity is a module. Use of particular entities is optional and extensible. A user will inherit the entities that they choose, and implement the desired functionality. Another modularisation occurs with the AGIEF Nodes. They communicate via interprocess conventions so that components can be split between multiple host computers.
Interprocess communication occurs via a central interface called the Coordinator, which is a single point of contact for all Entities and the shared system state. This also enables graphical user interfaces to be built to control and explore the system.
These concepts are expanded in the sections below.
Design Considerations
The various components of the system may have huge in-memory data-structures. This is an important consideration for persisting state, distributed operation, and ability to visualise the state.Processing to update the state of Worlds and Agents will be compute-intensive. Many AI methods can easily be accelerated by parallel execution. Therefore, the system can be broken down into many computing nodes, each tasked with performing a specific computational function on some part of the shared system state. We hope to support massively parallel hardware such as GPUs in these compute nodes.
We will write the bulk of the framework and initial algorithm implementations in Java. Others can extend on this, or develop against the framework in other languages. We will also write a graphical user interface using web technologies that will allow easy management of the system.
Perspectives on the system design
The architectural layers are shown in the diagram below. |
| Figure 1: 'Architectural Layers' |
Each layer is distinct, with strict separation. No layer has access to the layers above, which operate at a higher level of abstraction.
- State:
- State persistence: storage and retrieval of state of all parts of the system at every time step. This comprises the shared filesystem.
- Interprocess:
- Communications between all modules running in the system, locally and/or across a network.
- Provides a single point of contact via a local interface, to any part of the system (which may be running in different physical locations), for both control signals and state.
- Experiment:
- Provides all of the entities that are required for an experiment. These are expanded shortly.
- UI:
- The user interface that an experimenter uses to run experiments, debug and visualise results.
- The typical features would be:
- set up parameters of an experiment,
- run, stop, step through an experiment,
- save/load an experiment,
- visualise the state of any part of the experiment.
- Specific Experiments:
- This is defined by the person experimenting with the system. For example, a specific Agent that seeks light, a specific World that contains a light source, and an objective function that defines the time span for operation.
 |
| Figure 2: 'Services and Entities' |
The Coordinator and Database are services. The Coordinator is shown at the centre, as described earlier (Architecture section), being the primary point of contact for Entities and potentially other clients such as a Graphical User Interface.
A similar perspective is shown in an expanded diagram below that illustrates the Database API module and the distributed implementation of the Coordinator in the Interprocess layer, enabling Entities to run on separate machines. This is just one possible configurations; there can be multiple slaves, each with multiple entities.
Each bounding box indicates what we refer to as an AGIEF Node (or node for short). The node comprises a process that provides a context for execution of one or more entities, or other clients such as the GUI.
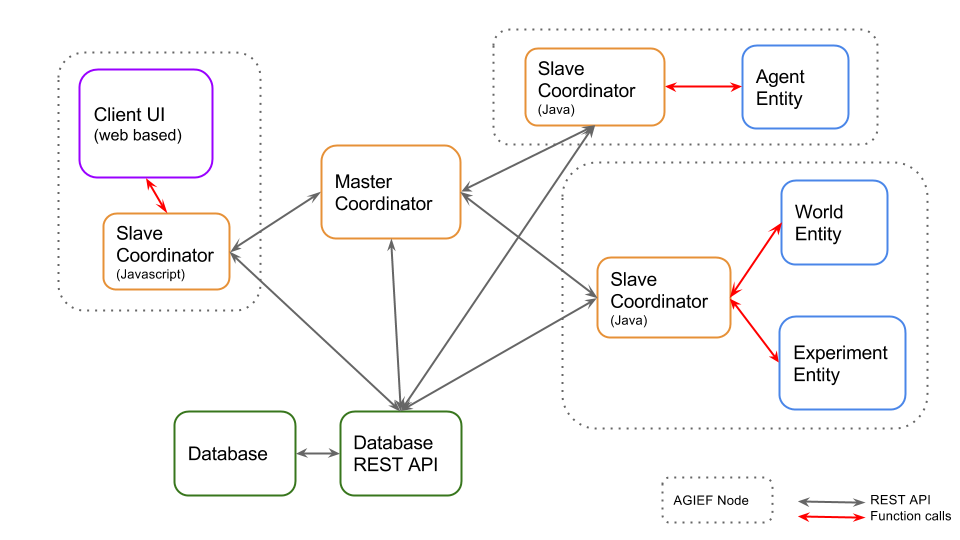 |
| Figure 3: 'AGIEF Nodes' |
A third perspective is the data model that represents the system in its entirety. This is the model implemented in the database.
 |
| Figure 4: 'Data Model' |
The data model stores the entire system state, including hierarchy and relationship between entities, as well as the state of each entity. With a RESTful API exposing the database, we have a shared filesystem accessible as a service, essential for distributed operation and restoring the system at any point in time.