By Gideon Kowadlo and David Rawlinson
In our last blog post, we discussed the repeating functional columnar structure of the neocortex, and the inconsistent terminology used to discuss it throughout the literature. As mentioned in that post, the function of the column is an important concept for understanding the function of the neocortex, and as a consequence, for designing algorithms that are inspired by the neocortex. We therefore require a clear nomenclature for discussing and working with these concepts.As promised, here is a follow-up post with definitions of columns and associated concepts. The definitions are based on a paper by Rinkus [1] (introduced in the previous post). For decades it was widely accepted that the structure of columns in the neocortex is uniform across species and individuals. Recent studies have shown that to be not entirely correct [3] (summarised here and in [4] ). Rinkus provides a well founded functional basis for the definition of columns. This approach is more meaningful and robust, and directly relevant to understanding the neocortex algorithmically.
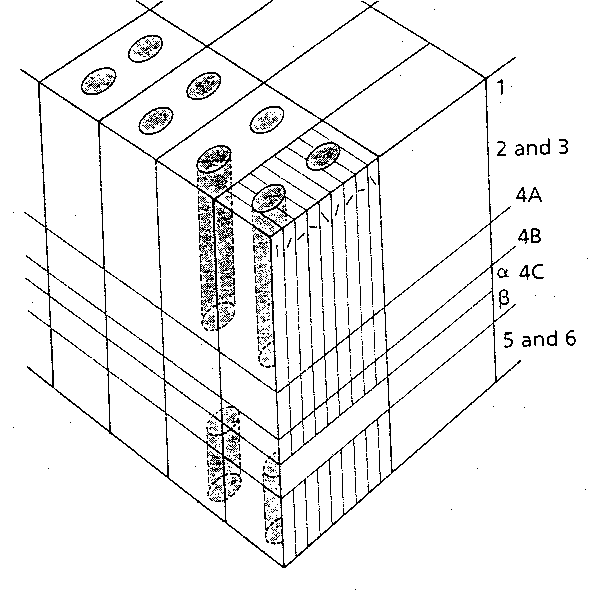 |
| Illustration of layers and columns in the neocortex. Reproduced from “Basic Cerebral Cortex Function with Emphasis on Vision” by Ben Best. |
Layer
Function
Although cells in any layer may connect to cells in all other layers, they do this only for cells within the same macrocolumn.
This means that columns extend through all cortex layers. Columns are organised perpendicularly to layers. Since the layers consist of different patterns of cell connectivity and type, layer distinctions are also functional distinctions.
Anatomy
Typically 5-7 layers, described as:- L1 Molecular Layer
- (non-cellular, just axons)
- [L2, L3] Small pyramidal cells (of two sizes)
- L4 Spherical neurons.
- [L5a, L5b] Large pyramidal cells (a & b often distinguished)
- L6 multiform layer
Macrocolumn (also referred to as a Region or Hypercolumn)
Function
“The function of a macrocolumn is to store sparse distributed representations of its overall input patterns, and to act as a recognizer of those patterns.” [1]Overall input includes bottom up input from thalamus and lower cortical areas, top down from higher cortical areas and horizontal from adjacent cortical areas. This is also referred to as the context. The macrocolumn responds to context dependent input patterns.
A standard definition of a macrocolumn is a set of cells that have the same receptive field. In this definition, we specify that all cells in the macrocolumn don’t necessarily have same learned receptive field, but the same potential receptive field.
Anatomy
- 300–600 μm
- 60 - 80 minicolumns per macrocolumn
Minicolumn
Function
A subset of cells in the macrocolumn, for which there is a winner take all (WTA) cell, for a given macrocolumn context (overall input pattern). According to this definition, the function of the minicolumn is to enforce sparseness.The fact that there is only one winner results in an SDR in the macrocolumn. Therefore, the macrocolumn output contains a signal from 1 winning cell in each minicolumn, in each layer (~70 cells in total per layer). In most implementations, WTA is implemented with a competitive process.
A standard definition of a minicolumn is that all cells within it describe a similar feature within that the receptive field of the macrocolumn. This will occur in most cases, but it emerges from the function, which is the basis of our definition.
Anatomy
- ~20 cells (physically localised)
- 20–50 μm
Potential Receptive Field
Function
A set of input bits that can be connected to a cell.Anatomy
A set of axons that potentially could be synapsed by the dendrites of a neuron.Learned Receptive Field
Function
The actual set of input bits synapsed to a cell after learning and the effects of mutual inhibition or self-organisation with its neighbours.Anatomy
The synapses formed by the dendrites of a neuron on input axons.Many researchers believe that the set of active cells in a single macrocolumn layer can be described as a Sparse Distributed Representation (SDR). We assume this to be the case in our definitions. SDRs can be understood as having the following properties:
- Attributes
- Compositionality
- Distribution
SDR: Attributes
A subset of an SDR that has some semantic meaning; 1 or more bits, NOT the whole set of active bits in an SDR.SDR: Compositionality
Compositionality of SDRs emerges from the fact that an SDR contains many attributes in combination.SDR: Distributed
A distributed representation is one that consists of multiple attributes, those attributes can exist independently, be shared between representations and overlap.References
[1] Rinkus G.J., “A cortical sparse distributed coding model linking mini- and macrocolumn-scale functionality”, Frontiers in Neuroanatomy, vol. 4, no. 17, 2010.[2] Rakic P., “Confusing cortical columns”, Proceedings of the National Academy of Sciences, vol. 105, no. 34, 2008.
[3] Meyer, Hanno S., et al. "Cellular organization of cortical barrel columns is whisker-specific." Proceedings of the National Academy of Sciences, vol. 110, no. 47, 2013.
[4] Herculano-Houzel, Suzana, et al. "The basic nonuniformity of the cerebral cortex." Proceedings of the National Academy of Sciences, vol. 105, no.34, 2008.
If I understand this, your account is quite different from Numenta's CLA:
ReplyDelete* you see every minicolumn having one active cell, whereas they see only one in every 50 minicolumns having an active cell - or having all its cells active if bursting.
* If your macrocolumns/regions correspond to CLA "regions", they are much smaller at ~70 minicolumns compared to their 2048+. But I think your macrocolumns are actually a finer grain, and CLA regions are intended to be more like functional areas (V1 etc)...