by David Rawlinson and Gideon Kowadlo
The FF direct pathway cannot be driven by feedback from higher levels alone: FF input is always needed to fully activate cells in the Sequence Memory. As a hierarchy of unsupervised classifiers, the FF pathways are similar to the Deep Learning hierarchy.
Prediction is specifically a process of activating Sequence Memory cells that represent FF input patterns that are likely to occur in the near future. Prediction changes Sequence Memory cells to a receptive state where they are more easily activated by future FF input. In this way, prediction makes classification of FF input more accurate. Improvement is due to the extra information provided by prediction, using both the history of Sequence Cell activation within the region and the history of activation of Sequence Memory cells within higher regions, the latter via the FB pathway.
It is probable that the FB pathway contains prediction data, possibly in addition to Sequence Memory cell state. This is described in MPF/HTM literature, but is not specifically encoded in existing CLA documentation.
Personally, I believe that prediction is synonymous with the generation of behaviour and that it has dual purposes; firstly, to enable regions to better understand future FF input, and secondly, to produce useful actions. A future article will discuss the topic of whether prediction and planning actions could be the same thing in the brain's internal representation. An indirect FB pathway is not shown in this diagram because it is not described in MPF/CLA literature.
Numenta also claim that there is a timing function in cortical prediction, that enables the region to know when specific cells will be driven active by FF input. Since this function is speculative, it is not shown in the diagram above. The timing function is reportedly due to cortical layer 5.
Introduction
The Memory Prediction Framework (MPF) is a general description of a class of algorithms. Numenta's Cortical Learning Algorithm (CLA) is a specific instance of the framework. Numenta's Hierarchical Temporal Memory (HTM) was an earlier instance of the framework. HTM and CLA adopt different internal representations so it is not as simple as CLA supersedes HTM.
This post will describe structure of the framework that is common to MPF, CLA and HTM, specifically some features that cause confusion to many readers.
For a good introduction to MPF/CLA/HTM see the Numenta CLA white paper.
The Hierarchy
The framework is composed as a hierarchy of identical processing units. The units are known as "regions" in CLA. The hierarchy is a tree-like structure of regions:
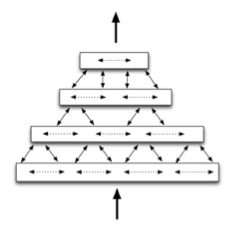 |
| MPF/CLA/HTM hierarchy of Regions. The large arrows show the direction of increasing abstraction. Smaller arrows show the flow of data between nearby regions in a single level of the hierarchy, and between levels of the hierarchy. Figure originally from Numenta. |
Regions communicate with other, nearby regions in the same level of the hierarchy. Regions also communicate with a few regions in a higher level of the hierarchy, and a few regions in a lower level of the hierarchy. Notionally, abstraction increases as you move towards higher levels in the hierarchy. Note that Hawkins and Blakeslee define abstraction as "the accumulation of invariances".
Regions
Biologically, each Region is a tiny patch of cortex. The hierarchy is constructed from lots of patches of cortex. Each piece of cortex has approximately 6 layers (there are small variations throughout the cortex, and the exact division between cortical layers in biology is a bit vague. Nature hates straight lines). Note that in addition to having only 6 layers, each cortical region is finite in extent within the cortex - i.e. it is only a tiny area on the surface of the cortex.
 |
| Cortical layers and connections between hierarchy levels. Each cortical region has about 6 structurally (i.e. also functionally) distinct layers. The hierarchy is composed of a tree of cortical regions, with connections between regions in different levels of the hierarchy. 3 key pathways are illustrated here. Each pathway is a carrier of distinct information content. The Feed-Forward pathways carry information UP the hierarchy levels towards increasing abstraction/invariance. The Feed-Back pathway carries information DOWN through hierarchy levels towards regions that represent more concrete, raw, unclassified inputs. Some pathways connect cortical regions directly, others indirectly (via other brain structures). Note that this image is a modified copy of one from Numenta, with additional labels and colours standardised to match the rest of this document. |
Levels and Layers
Newcomers to MPF/CLA/HTM theory sometimes confuse "cortical layers" and connections between regions placed in different "levels" of the hierarchy. We recommend everyone uses layers to talk about cortical layers and levels to talk about hierarchy levels, although the levels and layers are somewhat synonymous in English. I believe this confusion arises because readers expect to learn one new concept at a time, but in fact levels and layers are two separate things.
Pathways
There are several distinct routes that information takes through the hierarchy. Each route is called a "pathway". What is a pathway? In short, a pathway is a set of assumptions that allows us to make some broad statements about what components are connected, and how. We assume that the content of data in each pathway is qualitatively different. We also assume there is limited mixing of data between pathways, except where some function is performed to specifically combine the data.
Directions
There are two directions that have meaning within the MPF/CLA/HTM literature. These are feed-forward and feed-back. Feed-Forward (FF) means data travelling UP between hierarchy levels, towards increasing abstraction. Feed-Back (FB) means data travelling DOWN between hierarchy levels, with reducing abstraction and taking on more concrete forms closer to raw inputs.
3 Pathways
The 3 pathways typically discussed in the MPF/CLA/HTM literature are:
- FF direct (BLUE)
- FF indirect (GREEN)
- FB direct (RED)
Direct means that data travels from one cortical region to another, without a stop along the way at an intermediate brain structure. Indirect means that the data is passed through another brain structure en-route, and possibly modified or gated (filtered).
This does not mean that other pathways do not exist. There is likely a FB-indirect pathway from Cortex to Cortex via the Basal Ganglia, and direct connections between nearby Regions at the same level in the hierarchy. However, current canonical MPF/CLA theory does not assign roles to these pathways.
We will always use the same colours for these pathways.
 |
| The conceptual and biological arrangement of the MPF/CLA/HTM hierarchy. Left, the conceptual structure. Right, the physical arrangement of the hierarchy. Cortical processing occurs on the surface of the cerebrum, not inside it; the filling is mainly neuron axons connecting surface regions. FF (blue) and FB (red) pathways are shown. Moving between hierarchy levels involves routing data between different patches of cortex (surface). The processing Units - each, a separate region - here are labelled Unc where n is the hierarchy level and r is an identifier for each Region. Note that data from multiple regions is combined in higher levels of the hierarchy: For example, U2a receives FF data from U1a and U1b. Via the FB pathway, lower levels are able to exploit data from other subtrees. Some types of data relayed between hierarchy regions are relayed via deep brain structures, such as the Thalamus. We say these are "indirect" connections. The relays may modify / filter / gate the data en-route. |
Conceptual Region Architecture
MPF/CLA/HTM broadly outlines the architecture of each Region as follows. Each region has a handful of distinct functional components, namely: Spatial Pooler, Sequence Memory, and Temporal Pooler. Prediction is also a core feature of each Region, though it may not be considered a separate component. I believe that Hawkins would not consider this to be a complete list, as the CLA algorithm is still being developed and does not yet cover all cortical functions. Note that the conceptual entities described here do not imply structural boundaries or say anything about how this might look as a neural network.
The Spatial Pooler identifies common patterns in the FF direct input and replaces them with activation of a single cell (or, variable, or state, or label, depending on your preferred terminology). The spatial pooler is functioning as an unsupervised classifier to transform input patterns into abstract labels that represent specific patterns.
 |
| Key functional components of each Region. Note that every cellular Cortical layer of cells is believed to be performing some subset of these functions. It is not intended that each layer perform one of the functions. Where specifically described, the inputs and outputs of each pathway are shown. The CLA white paper does not specifically define how FB output is generated. It is possible that FB output contains predicted cells. Prediction is an integral function of the posited sequence memory cells, so whether it can be a separate component is debatable. However, conceptually, a sequence memory cell cannot be activated by prediction alone; FF ("bottom up") input is always needed to activate a cell. Prediction puts sequence memory cells into a receptive state for future activation by FF input. Regions receive additional data (e.g. from regions at higher hierarchy levels) when making their predictions. Prediction allows regions to better recognise FF input and predict future sequence cell activation. Note, from the existing CLA white paper it is not clear whether the FF indirect pathway involves Temporal Pooling. The white paper says that FF-indirect output originates in Layer 5 which is not fully described. |
The Sequence Memory models changes in the state of the spatial pooler over time. In other words, which cells or states follow which other cells/states? The Sequence Memory can be thought of as a Markov Chain of the states defined by the spatial pooler. Sequence Memory encodes information that enables predictions of future spatial pooler state.
The FF direct pathway cannot be driven by feedback from higher levels alone: FF input is always needed to fully activate cells in the Sequence Memory. As a hierarchy of unsupervised classifiers, the FF pathways are similar to the Deep Learning hierarchy.
Prediction is specifically a process of activating Sequence Memory cells that represent FF input patterns that are likely to occur in the near future. Prediction changes Sequence Memory cells to a receptive state where they are more easily activated by future FF input. In this way, prediction makes classification of FF input more accurate. Improvement is due to the extra information provided by prediction, using both the history of Sequence Cell activation within the region and the history of activation of Sequence Memory cells within higher regions, the latter via the FB pathway.
It is probable that the FB pathway contains prediction data, possibly in addition to Sequence Memory cell state. This is described in MPF/HTM literature, but is not specifically encoded in existing CLA documentation.
Personally, I believe that prediction is synonymous with the generation of behaviour and that it has dual purposes; firstly, to enable regions to better understand future FF input, and secondly, to produce useful actions. A future article will discuss the topic of whether prediction and planning actions could be the same thing in the brain's internal representation. An indirect FB pathway is not shown in this diagram because it is not described in MPF/CLA literature.
While Spatial Pooling tries to replace instantaneous input patterns with labels, Temporal pooling attempts to simplify changes over time by replacing common sequences with labels. This is a function not explicitly handled in Deep Learning methods, which are typically applied to static data. MPF/CLA/HTM is explicitly designed to handle a continuous stream of varying input.
Temporal pooling ensures that regions at higher levels in the hierarchy encode longer sequences of patterns, allowing the hierarchy to recognise long-term causes and effects. The input data for every region is different, ensuring that each region produces unique representations of different sub-problems. Spatial and Temporal pooling, plus the merging of multiple lower regions in a tree-like structure, all contribute to the uniqueness of each region's Sequence Memory representation.
Temporal pooling ensures that regions at higher levels in the hierarchy encode longer sequences of patterns, allowing the hierarchy to recognise long-term causes and effects. The input data for every region is different, ensuring that each region produces unique representations of different sub-problems. Spatial and Temporal pooling, plus the merging of multiple lower regions in a tree-like structure, all contribute to the uniqueness of each region's Sequence Memory representation.
Numenta also claim that there is a timing function in cortical prediction, that enables the region to know when specific cells will be driven active by FF input. Since this function is speculative, it is not shown in the diagram above. The timing function is reportedly due to cortical layer 5.
Mapping Region Architecture to Cortical Layers
As it stands CLA claims to explain (most of) cortex layers 2, 3 and 4. Hawkins et al are more cautious about their understanding of other cortical layers.
To try to present a clear picture of their stance, I have included a graphic (below) showing the functions of each biological cortex layer as defined by CLA. The graphic also shows the flows of data both between layers and between regions. Note that the flows given here are only those as described in the CLA white paper and Hawkins' new ideas on temporal pooling. Other sources do describe additional/alternative connections between cortical levels and regions. The exact interactions of each layer of neurons are somewhat messy and difficult to interpret.
 |
| Data flow between cortical layers as described in the CLA white paper. Every arrow in this diagram is the result of a specific comment or diagram in the white paper. This figure is mostly a repeat of the same information as in the second figure, using a different presentation format. I have speculatively coloured each arrow by content (i.e. pathway) , but don't rely on this interpretation. Inputs to L2/3,L4 and L5 from L1 are red because there are no cells in L1 to transform the FB input signal, therefore this must be FB data. The black arrow is black because I have no idea what data or pathway it is associated with! |
Summary
I hope this review of the terminology and architecture is helpful. Although the MPF/CLA/HTM framework is thoroughly and consistently documented, some of the details and concepts can be hard to picture, especially in the first encounter. The CLA White Paper does a good job of explaining Sparse Distributed Representations and spatial, temporal pooler implementations as biologically-inspired Sequence Memory cells. However, the grosser features of the posited hierarchy are not so thoroughly described.
It is worth noting that according to recent discussions on the NUPIC mailing list, the current NUPIC implementation of CLA does not correctly support multi-level hierarchies correctly. This problem is expected to be addressed in 2014, permitting multi-level hierarchies.
It is worth noting that according to recent discussions on the NUPIC mailing list, the current NUPIC implementation of CLA does not correctly support multi-level hierarchies correctly. This problem is expected to be addressed in 2014, permitting multi-level hierarchies.
Thanks very much, David and Gideon! This has cleared a few things up for me. Are you aware of any major developments/insights by Numenta or others (including yourselves) since you wrote this article? Are there any parts of this article that are now known to be incorrect or that have been supported by more evidence? Thanks!
ReplyDeleteHi Joseph thanks for your comment. This article is pretty old... we are currently writing a new series summarizing everything we have learnt and find relevant. So far it's mostly the bio side but algorithms part is coming soon.
ReplyDeleteHave a look at :
http://blog.agi.io/2015/11/how-to-build-general-intelligence.html
and
http://blog.agi.io/2015/12/how-to-build-general-intelligence.html
Keep watching for the next post in the series which will try to interpret all this from a computational perspective. We're pretty excited about that one. It's already drafted but being reviewed internally.
Regarding the algorithm insights, we have spent some time looking at temporal sequences - LSTMs and Predictive Coding particularly. The approach used in Numenta's HTM is Temporal Slowness. We prefer Predictive Coding but these are both ways to implement Temporal Pooling.
Thanks very much, Dave. I'll get reading!
ReplyDelete