by David Rawlinson and Gideon Kowadlo
Article Series
This is the first of 3 articles about temporal pooler design for Numenta's Cortical Learning Algorithm (CLA) and related methods (e.g. HTM/MPF). It has limited relevance to Deep Belief Networks.
This first part will describe some of the considerations, objectives and constraints on temporal pooler design. We will also introduce some useful terminology. Part 2 will examine Jeff Hawkins' new temporal pooler design. Part 3 will examine an alternative temporal pooler design we are successfully using in our experiments.
We will use the abbreviation TP for Temporal Pooler to save repeating the phrase.
Purpose of the Temporal Pooler
What is the purpose of the Temporal Pooler? The TP is a core process in construction of a hierarchy of increasingly abstract symbols from input data. In a general-purpose algorithm designed to accept any arbitrary stream of data, building symbolic representations, or associating a dictionary of existing symbols with raw data, is an exceedingly difficult problem. The MPF/CLA/HTM family of algorithms seeks to build a dictionary of symbols by looking for patterns in observed data, specifically:a) inputs that occur together at the same time
b) sequences of inputs that reliably occur one after another
The Spatial Pooler's job is to find the first type of pattern: Inputs that occur together. The TP's job is to find the second type of pattern - inputs that occur in predictable sequences over time. MPF calls these patterns "invariances". Repeated experience allows discovery of invariances: reliable association in time and space binds inputs together as symbols.
MPF/CLA/HTM claims that abstraction is equivalent to the accumulation of invariances. For example, a symbol representing "dog" would be invariant to the pose, position, and time of experiencing the dog. This is an exceptionally powerful insight, because it opens the door to an algorithm for automatic symbol definition.
What is a symbol? Symbols are the output of Classification. There must be consistent classification of the varying inputs that collectively represent a common concept, such as an entity or action. There must also be substitution of the input with a unique label for every possible classification outcome.
The symbol represents the plethora of experiences (i.e. input data) that cumulatively give the symbol its meaning. Embodiment of the symbol can be as simple as the firing of a single neuron. Symbols that represent a wider variety of input are more abstract; symbols that represent only a narrow set of input are more concrete.
Markov Chains
We will evaluate and compare TP functions using some example problems. We will be using Markov Chains to define the example problems. The Markov property is very simple; each state only depends on the state that preceded it. All information about the system is given by the identity of the current state. The current state alone is enough to determine the probability of transitioning to any other state.
Markov chains are normally drawn as graphs, with states being represented as vertices (aka nodes, typically presented as circles or ellipses). Changes in system state are represented by transitions between vertices in the graph. Edges in the graph represent potential changes, usually annotated with transition probabilities; there may be more than one possible future state from the current state. When represented as a Markov chain, the history of a system is always a sequence of visited states without forks or joins.
Here is an example Markov Chain representing a cycle of 4 states (A,B,C,D). Each state has a colour. The colour of the current state is observable. This graph shows that Red comes after Black. Green comes after Red. Blue follows Green, and Black follows Blue:Markov chains are normally drawn as graphs, with states being represented as vertices (aka nodes, typically presented as circles or ellipses). Changes in system state are represented by transitions between vertices in the graph. Edges in the graph represent potential changes, usually annotated with transition probabilities; there may be more than one possible future state from the current state. When represented as a Markov chain, the history of a system is always a sequence of visited states without forks or joins.
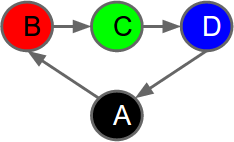 |
| A simple Markov Chain shown as a graph. Vertices (circles) represent states. There are 4 states. Edges represent possible transitions between states. The color of each circle indicates what is observed in the corresponding state. |
 |
| A Markov chain with 7 states. State A can be followed by B or E with equal probability. Both states D and G are always followed by state A. This system represents 2 sequences of colours, separated by black. Each sequence is equally likely to occur, but once the sequence starts it is always completed in full. |
First-Order Sequence Memory Representation
If we allow an MPF hierarchy to observe the system described by the Markov Chain above, the hierarchy will construct a model of it. Spatial pooling tries to identify instantaneous patterns (which will cause it to learn the set of observed colours). Temporal pooling attempts to find sequential patterns (frequently-observed sequences of colours). More simply put, an MPF hierarchy will try to learn to predict the sequences of colours.How accurately the hierarchy can predict colours will depend on the internal model it produces. We know that the "real" system has 2 sequences of colours (RGB and GBR). We know that there is only uncertainty when the current state is Black.
However, lets assume the MPF hierarchy consists of a single region. Let's say the region has 4 cells, that learn to fire uniquely on observation of each of the 4 colours. The Sequence Memory in the region learns the order of cell firing - i.e. it predicts which cell will fire next, given the current cell. It only uses the current active cell to predict the next active cell.
The situation we have described above can be drawn as a Markov Chain like this:
 |
| A Markov chain constructed from first-order prediction given observations from the 7-state system shown in the previous figure. |
The reason for the lack of predictive ability is that we are only using the current colour of our model to predict the next colour. This is known as first-order prediction (i.e. Markov order=1). If we used a longer history of observations, we could predict correctly in every case except Black, where we could be right half the time. Using a "longer" history to predict is known as variable-order prediction (variable because we don't know, or limit, how much history is needed).
Uncertainty and the Newtonian experience
In today's physics, non-determinism (future not decided) or at least in-determinism (inability to predict) are widely and popularly accepted. But although these effects may dominate on very small and large scales, for much of human-scale experience the physical world is essentially a predictable, Newtonian system. Indeed, human perception encodes Newtonian laws so exactly that acceleration of objects induces an expectation of animate agency.
In a Newtonian world, every action is "explained" or caused by some other physical event; it is simply necessary to have a sufficiently comprehensive understanding & measurement to be able to discover the causes of all observed events.
This intuition is important because it motivates the construction of an arbitrarily large hierarchy of symbols and their relations in time and space, with the expectation that somewhere in that hierarchy all events can be understood. It doesn't matter that some events cannot be explained; we just need to get enough practical value to motivate construction of the hierarchy. The Newtonian nature of our experiences at human scale means that most external events are comprehensible and predictable.
Finding Higher-Order Patterns in Markov Chains
The use of longer sequences of colours to better explain (predict) the future shows that confusing, unpredictable systems may become predictable when more complex causes are understood. Longer histories (higher-order representations) can reveal more complex sequences that are predictable, even when the simpler parts of these patterns are not predictable by themselves.The "Newtonian world" assumption gives us good reason to expect that a lot of physical causes are potentially predictable, given a suitably complex model and sufficient data. Even human causes are often predictable. It is believed that people develop internal models of third party behaviour (e.g. "theory of mind"), which may help with prediction. This evidence motivates us to try to discover and model these causes as part of an artificial general intelligence algorithm.
Therefore, one purpose of the MPF hierarchy is to construct higher-order representations of an observed world, in hope of being able to find predictable patterns that explain as many events as possible. Given this knowledge, an agent can use the hierarchy to make good, informed decisions.
Constructing Variable-Order Sequences using First-Order Predictions
There is one final concept to introduce before we can discuss some temporal pooler implementations. The final concept is ways of representing variable-order sequences of cell activation in a Sequence Memory. This is not trivial because the sequences can be of unlimited length and complexity, (depending on the data). However, for practical reasons, the resources used must be limited in some way. So, how can arbitrarily complex structures be represented using a structure of limited complexity?Let's define a sequence memory as a set of cells, where each cell represents a particular state. Let's specify a fixed quantity of cells, and to encode all first-order transitions between these cells. All such pairwise transitions can be encoded in a matrix of dimension cells x cells. This means that cells only trigger each other individually; only pairs of cells can participate in each sequence fragment.
So, how can longer sequences be represented in the matrix? How can we differentiate between occurrences of the same observation in the context of different sequences?
 |
| The "state splitting" method of creating a variable-order memory using only first-order relationships between cells. This is part of a figure from Hawkins, George and Niemasik's "Sequence memory for prediction, inference and behaviour" paper. In this example there are 5 states A,B,C,D,E. We observe the sequences A,C,D and B,C,E. In subfigure (c), we see that for each state A,...,E there are a bunch of cells that respond to it. However, each cell only responds to specific instances of these states. Specifically, there are two cells (C1 and C2) that respond to state C. C1 responds to state C only after state A. C2 responds to an observation of state C only after state B. If we have only a single cell that responds to C, we lose the ability to predict D and E (see subfigure (d)). With two cells uniquely responding to specific instances of C (see subfigure (e)), we gain the ability to predict states D and E. Prediction is improved by splitting state C, giving us a variable-order memory. |
In the current CLA implementation, the same feature is achieved by having "columns" of cells that all respond to the same input in different sequence contexts (i.e. given a different set of prior cells). CLA says they share the same "proximal dendrite", which defines the set of input bits that activate the cell. In our paper, we showed how a radial inhibition function could induce sequence-based specialization of Self-Organising Map (SOM) cells into a variable-order sequence memory:
| Creation of a variable order sequence memory in a Self-Organising Map (SOM) using inhibition. The circles represent cells that respond to the same input, in this case the letters A,B,C or D. We can use first-order sequence relationships to cause specialization of cells to specific instances of each letter. Blue lines represent strong first-order sequence relationships. The edge i-->k promotes k responding to "B" and inhibits x. Eventually k only responds to AB and x only responds to CB. |
So, returning to our example problem above with 2 sequences of colours, RGB and GBR, what is the ideal sequence-memory representation using a finite set of cells, multiple cells for each input depending on sequence context, and only first-order relationships between cells? One good solution is shown below:
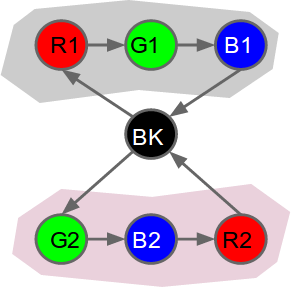 |
| Example modelling of our test problem using a variable order sequence memory. We have 7 cells in total. Each cell responds to a single colour. Only one cell responds to black (BK). Having two cells responding to each colour R,G and B allows accurate prediction of all transitions, except where there is genuine uncertainty (i.e. edges originating at black). The temporal pooler component should then be able to identify the two sequences (grey and pink shading) by learning these predictable sequences of cell activations. The temporal pooler will replace each sequence with a single "label", which might be a cell that fires continuously for the duration of each sequence. Cells watching the temporal pooler output will notice fewer state changes, i.e. a more stable output. |
Well, we know that there are in fact 2 sequences, and a "decision" state that switches between them. The ideal sequence-memory and temporal pooler implementation would track all predictable state changes, and replace these sequences with labels that persist for the duration of each sequence. In this way, the problem is simplified; other cells watching the temporal pooler output would observe fewer state changes - only switching between Black, Sequence #1 and Sequence #2.
 |
| Markov Chain that is experienced by an observer of the output from the ideal sequence-memory and temporal pooler modelling shown in the figure above. The problem has been reduced from 7 states to 3. State transitions are only observed when transitioning to or from the Black state (BK). Otherwise, a constant state is observed. |
No comments :
Post a Comment